分布式与大数据的设计与实现[1]:大数据之路坑很多,熟练掌握shell很有必要
栏目:分布式与大数据 作者:admin 日期:2018-10-31 评论:0 点击: 663 次
(1)非常陡峭的学习曲线。刚接触这个领域的人经常会被各种框架,各种技术,各种概念搞的晕头转向。不像经过几十年发展的数据库,一个系统可以解决大部分数据处理需求,Hadoop 等大数据生态里的一个系统往往在一些数据处理场景上比较擅长,另一些场景凑合能用,还有一些场景完全无法满足需求。结果就是需要好几个系统来处理不同的场景。
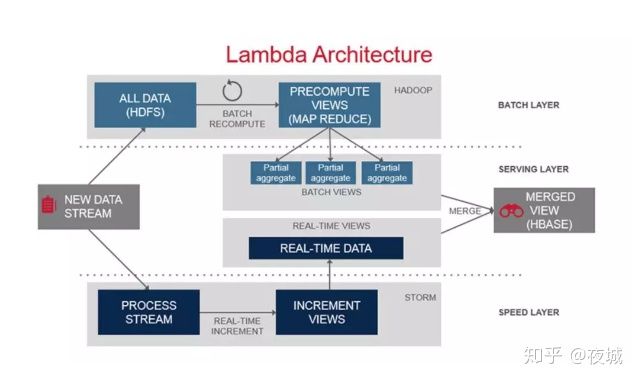
上图是一个典型的 lambda 架构,只是包含了批处理和流处理两种场景,就已经牵涉到至少四五种技术了,还不算每种技术的可替代选择。再加上实时查询、交互式分析、机器学习等场景,每个场景都有几种技术可以选择,每个技术涵盖的领域还有不同方式的重叠。结果就是一个业务经常需要使用四五种以上的技术才能支持好一个完整的数据处理流程。加上调研选型,需要了解的数目还要多得多。
(2)开发和运行效率低下。因为牵涉到多种系统,每种系统有自己的开发语言和工具,开发效率可想而知。又因为采用了多套系统,数据需要在各个系统之间传输,也造成了额外的开发和运行代价,数据的一致也难以保证。在很多机构,实际上一半以上的开发精力花在了数据在各个系统之间的传输上。
(3)复杂的运维。多个系统,每个需要自己的运维,带来更高的运维代价的同时也提高了系统出问题的可能。
(4)数据质量难以保证。数据出了问题难以跟踪解决。
分布式与大数据的设计与实现[1]:大数据之路坑很多,熟练掌握shell很有必要:等您坐沙发呢!
发表评论
------====== 本站公告 ======------
金丝燕网,一个严谨的网站!
热门文章
- Spring中@Cacheable的用法
- Unsupported major.minor version 5...
- BIG5编码
- Spring中DataIntegrityViolation...
- 《Web前端黑客技术揭秘》pdf下载
- Class.getResource和ClassLoader...
- JRE与JDK的区别
- serialVersionUID作用
- java String.split()函数的用法分析
- Eclipse注释模板设置详解
- json教程系列(5)-json错误解析net....
- json教程系列(4)-optXXX方法的使...
- ArrayList循环遍历并删除元素的常见...
- freemarker空值的处理
- log4j使用介绍
最新评论
免责声明:本站所有pdf书籍和教程视频均来自于互联网,由热心读者共同搜集,仅限于个人学习与研究,严禁用于商业用途。
原作者如果认为本站侵犯了您的版权,请及时告知,本站会立即删除!
金丝燕网站 Copyright (c) 2019 www.swiftlet.net All rights reserved 备案号:京ICP备14057001号-1
Powered by swiftlet.