Apache common-poolпЉМcommon-dbcpжЇРз†БиІ£иѓїдЄО僺豰汆еОЯзРЖеЙЦжЮР
ж†ПзЫЃ:зЉУе≠ШиЃЊиЃ° дљЬиАЕ:admin жЧ•жЬЯ:2015-03-04 иѓДиЃЇ:1 зВєеЗї: 2,085 жђ°
僺豰汆е∞±жШѓдї•"з©ЇйЧіжНҐжЧґйЧі"зЪДдЄАзІНеЄЄзФ®зЉУе≠ШжЬЇеИґпЉМињЩйЗМзЪД"жЧґйЧі"зЙєжМЗеИЫеїЇжЧґйЧігАВе¶ВжЮЬдЄАзІНеѓєи±°зЪДеИЫеїЇињЗз®ЛйЭЮеЄЄиАЧжЧґзЪДиѓЭпЉМйВ£дєИиѓЈдљњзԮ僺豰汆гАВдїОеЖЕйГ®еОЯзРЖзЃАеНХзЪДиѓіпЉМ僺豰汆жКАжЬѓе∞±жШѓе∞ЖеИЫеїЇзЪДеѓєи±°жФЊеИ∞дЄАдЄ™еЃєеЩ®дЄ≠пЉМзФ®еЃМдєЛеРОдЄНжШѓйФАжѓБиАМжШѓеЖНжФЊеЫЮиѓ•еЃєеЩ®пЉМиЃ©еЕґдїЦзЪДеѓєи±°и∞ГзФ®пЉМ僺豰汆дЄ≠ињШжґЙеПКеИ∞дЄАдЇЫйЂШзЇІзЪДжКАжЬѓпЉМжѓФе¶ВињЗжЬЯйФАжѓБпЉМ襀熳еЭПжЧґйФАжѓБпЉМеѓєи±°жХ∞иґЕињЗ汆姲е∞ПйФАжѓБпЉМ僺豰汆дЄ≠ж≤°жЬЙеПѓзФ®з©ЇйЧ≤еѓєи±°жЧґз≠ЙеЊЕз≠Йз≠ЙгАВ
僺豰汆жКАжЬѓпЉМеЬ®жХ∞жНЃеЇУињЮжО•ињЗз®ЛдЄ≠дљњзФ®зЪДжѓФиЊГе§ЪпЉМе∞ЖеОЯжЬЙзЪДжЬ™дљњзФ®ињЮжΕ汆зЪДжХ∞жНЃеЇУиЃњйЧЃжУНдљЬжФєжИРињЮжΕ汆жЦєеЉПпЉМжАІиГљжЬЙдЇЖйЭЮеЄЄе§ІзЪДжПРеНЗгАВжЬАињСеЬ®еБЪдЄАдЄ™еЖЕйГ®жµЛиѓХеЈ•еЕЈз±їзЪДдЉШеМЦеЈ•дљЬдЄ≠жО•иІ¶еИ∞дЇЖињЮжΕ汆пЉМдЇЛеЃЮиѓБжШОпЉМзїПињЗдЄ§жђ°жФєйА†пЉМеОЯжЭ•дЄАдЄ™жѓФиЊГе§ІзЪДжµЛиѓХз±їйЬАи¶Б500е§ЪзІТпЉМзђђдЄАжђ°дЉШеМЦеРОеП™йЬАи¶Б300е§ЪзІТпЉМзђђдЇМжђ°жФєзФ®ињЮжΕ汆дєЛеРОеРМдЄАдЄ™жµЛиѓХз±їеП™йЬАи¶Б80е§ЪзІТгАВдЄЛйЭҐжШѓжФєйА†ињЗз®ЛдЄ≠зЪДдЄАдЇЫжАїзїУгАВ
apacheзЪДcommon-poolзЪДеЈ•еЕЈеМЕж؃僺豰汆жКАжЬѓзЪДдЄАзІНеЕЈдљУеЃЮзО∞гАВињЩйЗМеЕИзРЖиІ£еЗ†дЄ™ж¶Вењµ:
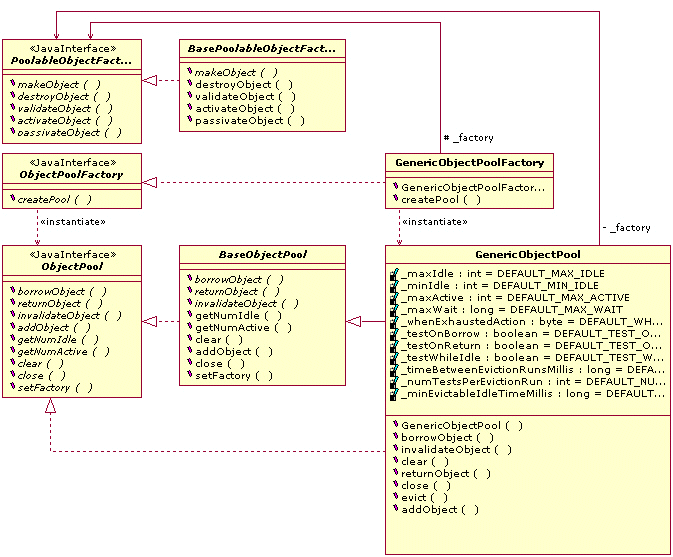
僺豰汆(ObjectPoolжО•еП£): еПѓдї•жККеЃГиЃ§дЄЇжШѓдЄАзІНеЃєеЩ®пЉМеЃГжШѓзФ®жЭ•и£Е汆僺豰зЪДпЉМеєґдЄФеМЕеРЂдЇЖзФ®жЭ•еИЫ忯汆僺豰зЪДеЈ•еОВеѓєи±°гАВ
汆僺豰:е∞±жШѓи¶БжФЊеИ∞汆偺еЩ®дЄ≠зЪДеѓєи±°пЉМзРЖиЃЇдЄКеПѓдї•жШѓдїїдљХеѓєи±°гАВ
僺豰汆壕еОВ(ObjectPoolFactoryжО•еП£):зФ®жЭ•еИЫ忯僺豰汆зЪДеЈ•еОВпЉМињЩдЄ™ж≤°дїАдєИе•љиѓізЪДгАВ
汆僺豰壕еОВ(PoolableObjectFactoryжО•еП£):зФ®жЭ•еИЫ忯汆僺豰пЉМе∞ЖдЄНзФ®зЪД汆僺豰ињЫи°МйТЭеМЦ(passivateObject)пЉМеѓєи¶БдљњзФ®зЪД汆僺豰ињЫи°МжњАжії(activeObject)пЉМ僺汆僺豰ињЫи°Мй™МиѓБ(validateObject)пЉМеѓєжЬЙйЧЃйҐШзЪД汆僺豰ињЫи°МйФАжѓБ(destroyObject)з≠ЙеЈ•дљЬгАВ
僺豰汆дЄ≠е∞Би£ЕдЇЖеИЫеїЇпЉМиОЈеПЦпЉМељТињШпЉМйФАжѓБ汆僺豰зЪДиБМиі£пЉМељУзДґињЩдЇЫеЈ•дљЬйГљжШѓйАЪињЗ汆僺豰壕еОВжЭ•еЃЮжЦљзЪДпЉМеЃєеЩ®еЖЕйГ®ињШжЬЙдЄАдЄ™жИЦе§ЪдЄ™зФ®жЭ•зЫЫ汆僺豰зЪДеЃєеЩ®гАВ僺豰汆дЉЪеѓєеЃєеЩ®е§Іе∞ПпЉМе≠ШжФЊжЧґйЧіпЉМиЃњйЧЃз≠ЙеЊЕжЧґйЧіпЉМз©ЇйЧ≤жЧґйЧіз≠Йз≠ЙињЫи°МдЄАдЇЫжОІеИґпЉМеЫ†дЄЇеПѓдї•ж†єжНЃйЬАи¶БжЭ•и∞ГжХіињЩдЇЫиЃЊзљЃгАВ
ељУйЬАи¶БжЛњдЄА䪙汆僺豰зЪДжЧґеАЩпЉМе∞±дїОеЃєеЩ®дЄ≠еПЦеЗЇдЄАдЄ™пЉМе¶ВжЮЬеЃєеЩ®дЄ≠ж≤°жЬЙзЪДиѓЭпЉМиАМдЄФеПИж≤°жЬЙиЊЊеИ∞еЃєеЩ®зЪДжЬАе§ІйЩРеИґпЉМйВ£дєИе∞±и∞ГзԮ汆僺豰壕еОВпЉМжЦ∞еїЇдЄА䪙汆僺豰пЉМеєґи∞ГзФ®еЈ•еОВзЪДжњАжіїжЦєж≥ХпЉМеѓєеИЫеїЇзЪДеѓєи±°ињЫи°МжњАжіїпЉМй™МиѓБз≠ЙдЄАз≥їеИЧжУНдљЬгАВе¶ВжЮЬеЈ≤зїПиЊЊеИ∞汆偺еЩ®зЪДжЬАе§ІеАЉпЉМиАМ僺豰汆дЄ≠еПИзїПж≤°жЬЙз©ЇйЧ≤зЪДеѓєи±°пЉМйВ£дєИе∞ЖдЉЪзїІзї≠з≠ЙеЊЕпЉМзЫіеИ∞жЬЙжЦ∞зЪДз©ЇйЧ≤зЪД僺豰襀䪥ињЫжЭ•пЉМељУзДґињЩдЄ™з≠ЙеЊЕдєЯжШѓжЬЙйЩРеЇ¶зЪДпЉМе¶ВжЮЬиґЕеЗЇдЇЖињЩдЄ™йЩРеЇ¶пЉМ僺豰汆е∞±дЉЪжКЫеЗЇеЉВеЄЄгАВ
"еЗЇжЭ•жЈЈпЉМжАїжШѓи¶БињШзЪД"пЉМ汆僺豰дєЯжШѓе¶Вж≠§пЉМељУе∞ЖзФ®еЃМзЪД汆僺豰ељТињШеИ∞僺豰汆дЄ≠зЪДжЧґеАЩпЉМ僺豰汆дЉЪи∞ГзԮ汆僺豰壕еОВ僺胕汆僺豰ињЫи°Мй™МиѓБпЉМе¶ВжЮЬй™МиѓБдЄНйАЪињЗеИЩ襀聧䪯жШѓжЬЙйЧЃйҐШзЪДеѓєи±°пЉМе∞ЖдЉЪ襀йФАжѓБпЉМеРМж†Је¶ВжЮЬеЃєеЩ®еЈ≤зїПжї°дЇЖпЉМињЩдЄ™ељТињШ汆僺豰е∞ЖеПШзЪД"жЧ†еЃґеПѓељТ"пЉМдєЯдЉЪ襀йФАжѓБпЉМе¶ВжЮЬдЄНе±ЮдЇОдЄКйЭҐдЄ§зІНжГЕеЖµпЉМ僺豰汆е∞±дЉЪи∞ГзФ®еЈ•еОВеѓєи±°е∞ЖеЕґйТЭеМЦеєґжФЊеЕ•еЃєеЩ®дЄ≠гАВеЬ®жХідЄ™ињЗз®ЛдЄ≠пЉМжњАжіїпЉМж£АжЯ•пЉМйТЭеМЦе§ДзРЖйГљдЄНжШѓењЕй°їзЪДпЉМеЫ†ж≠§жИСдїђеЬ®еЃЮзО∞PoolableObjectFactoryжО•еП£зЪДжЧґеАЩпЉМдЄАиИђдЄНдљЬе§ДзРЖпЉМзїЩз©ЇеЃЮзО∞еН≥еПѓпЉМжЙАдї•иѓЮзФЯдЇЖBasePoolableObjectFactoryгАВ
ељУзДґдљ†дєЯеПѓдї•е∞Жи¶БеЈ≤жЬЙзЪДеѓєи±°еИЫеїЇе•љпЉМзДґеРОйАЪињЗaddObjectжФЊеИ∞僺豰汆дЄ≠еОїпЉМдї•е§ЗеРОзФ®гАВдЄЇдЇЖз°ЃдњЭ僺僺豰汆зЪДиЃњйЧЃйГљжШѓзЇњз®ЛеЃЙеЕ®зЪДпЉМжЙАжЬЙеѓєеЃєеЩ®зЪДжУНдљЬйГљењЕй°їжФЊеЬ®synchronizedдЄ≠.
еЬ®apacheзЪДcommon-poolеЈ•еЕЈеЇУдЄ≠жЬЙ5зІН僺豰汆:GenericObjectPoolеТМ GenericKeyedObjectPoolпЉМSoftReferenceObjectPoolпЉМStackObjectPoolпЉМStackKeyedObjectPoolгАВ
дЇФзІН僺豰汆еПѓеИЖдЄЇдЄ§з±їпЉМдЄАз±їжШѓжЧ†keyзЪД:
дЄАз±їжШѓжЬЙkeyзЪД:
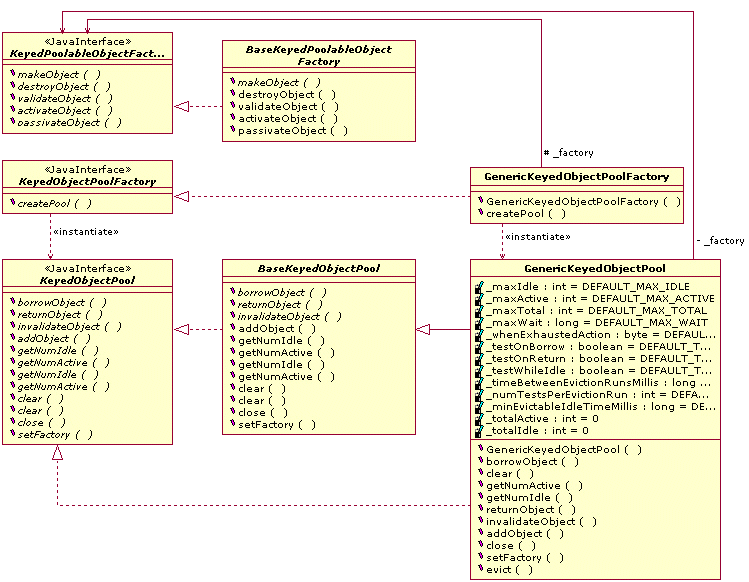
еЙНйЭҐдЄ§зІНзФ®CursorableLinkedListжЭ•еБЪеЃєеЩ®пЉМSoftReferenceObjectPoolзФ®ArrayListеБЪеЃєеЩ®пЉМдЄАжђ°жАІеИЫеїЇжЙАжЬЙ汆еМЦеѓєи±°пЉМеєґеѓєеЃєеЩ®дЄ≠зЪДеѓєи±°ињЫи°МдЇЖиљѓеЉХзФ®(SoftReference)е§ДзРЖпЉМдїОиАМдњЭиѓБеЬ®еЖЕе≠ШеЕЕиґ≥зЪДжЧґеАЩ汆僺豰дЄНдЉЪиљїжШУ襀jvmеЮГеЬЊеЫЮжФґпЉМдїОиАМеЕЈжЬЙеЊИеЉЇзЪДзЉУе≠ШиГљеКЫ. жЬАеРОдЄ§зІНзФ®StackеБЪеЃєеЩ®. дЄНеЄ¶keyзЪД僺豰汆жШѓеѓєеЙНйݥ汆жКАжЬѓеОЯзРЖзЪДдЄАзІНзЃАеНХеЃЮзО∞пЉМеЄ¶keyзЪДзЫЄеѓєе§НжЭВдЄАдЇЫпЉМеЃГдЉЪе∞Ж汆僺豰жМЙзЕІkeyжЭ•ињЫи°МеИЖз±їпЉМеЕЈжЬЙзЫЄеРМзЪДkey襀еИТеИЖеИ∞дЄАзїДз±їеИЂдЄ≠пЉМеЫ†ж≠§жЬЙе§Ъе∞СдЄ™keyпЉМе∞±дЉЪжЬЙе§Ъе∞СдЄ™еЃєеЩ®гАВ дєЛжЙАдї•йЬАи¶БеЄ¶keyзЪДињЩзІН僺豰汆пЉМжШѓеЫ†дЄЇжЩЃйАЪзЪД僺豰汆йАЪињЗmakeObject()жЦєж≥ХеИЫеїЇзЪДеѓєи±°еЯЇжЬђдЄКйГљжШѓдЄАж®°дЄАж†ЈзЪДпЉМеЫ†дЄЇж≤°ж≥ХдЉ†йАТеПВжХ∞жݕ僺汆僺豰ињЫи°МеЃЪеИґгАВ
еЫ†ж≠§еЫЫзІН汆僺豰зЪДеМЇеИЂдЄїи¶БдљУзО∞еЬ®еЖЕйГ®зЪДеЃєеЩ®зЪДеМЇеИЂпЉМStackйБµеЊ™"еРОињЫеЕИеЗЇ"зЪДеОЯеИЩеєґиГљдњЭиѓБзЇњз®ЛеЃЙеЕ®пЉМCursorableLinkedListжШѓдЄАдЄ™еЖЕйГ®зФ®жЄЄж†З(cursor)жЭ•еЃЪдљНељУеЙНеЕГзі†зЪДеПМеРСйУЊи°®пЉМжШѓйЭЮзЇњз®ЛеЃЙеЕ®зЪДпЉМдљЖжШѓиГљжї°иґ≥еѓєеЃєеЩ®зЪДеєґеПСдњЃжФє.ArrayListжШѓйЭЮзЇњз®ЛеЃЙеЕ®зЪДпЉМдЊњеИ©жЦєдЊњзЪДеЃєеЩ®гАВ
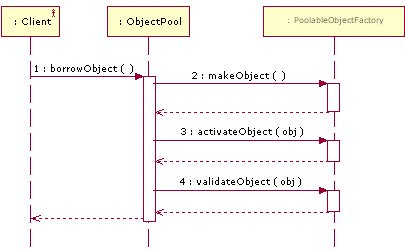
дљњзԮ僺豰汆зЪДдЄАиИђж≠•й™§:еИЫеїЇдЄА䪙汆僺豰壕еОВпЉМе∞Жиѓ•еЈ•еОВж≥®еЕ•еИ∞僺豰汆дЄ≠пЉМељУи¶БеПЦ汆僺豰пЉМи∞ГзФ®borrowObjectпЉМељУи¶БељТињШ汆僺豰жЧґпЉМи∞ГзФ®returnObjectпЉМйФАжѓБ汆僺豰и∞ГзФ®clear()пЉМе¶ВжЮЬи¶БињЮ汆僺豰壕еОВдєЯдЄАиµЈйФАжѓБпЉМеИЩи∞ГзФ®close()гАВдЄЛйЭҐжШѓдЄАдЇЫжЧґеЇПеЫЊпЉЪ
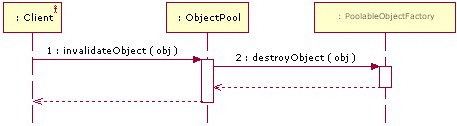
borrowObject:
returnObject:
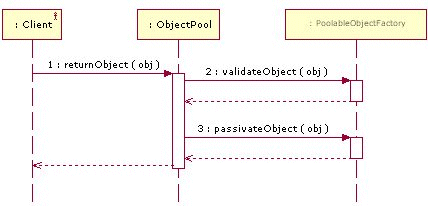
invalidateObject:
apacheзЪДињЮжΕ汆壕еЕЈеЇУcommon-dbcpжШѓcommon-poolеЬ®жХ∞жНЃеЇУиЃњйЧЃжЦєйЭҐзЪДдЄАдЄ™еЕЈдљУеЇФзФ®.ељУеѓєcommon-poolзЖЯжВЙдєЛеРО, еѓєcommon-dbcpе∞±еЊИе•љзРЖиІ£дЇЖ. еЃГйАЪињЗеѓєеЈ≤жЬЙзЪДConnection, Statmentеѓєи±°еМЕи£ЕжИР汆僺豰PoolableConnection, PoolablePreparedStatement. зДґеРОеЬ®ињЩдЇЫ汆еМЦзЪДеѓєи±°дЄ≠, жМБжЬЙдЄА䪙僺僺豰汆зЪДеЉХзФ®, еЬ®еЕ≥йЧ≠зЪДжЧґеАЩ, дЄНињЫи°МзЬЯж≠£зЪДеЕ≥йЧ≠е§ДзРЖ, иАМжШѓйАЪињЗи∞ГзФ®:
_pool.returnObject(this);
жИЦиАЕ
_pool.returnObject(_key,this);
ињЩж†ЈдЄАеП•, е∞ЖињЮжО•еѓєи±°жФЊеЫЮињЮжΕ汆дЄ≠.
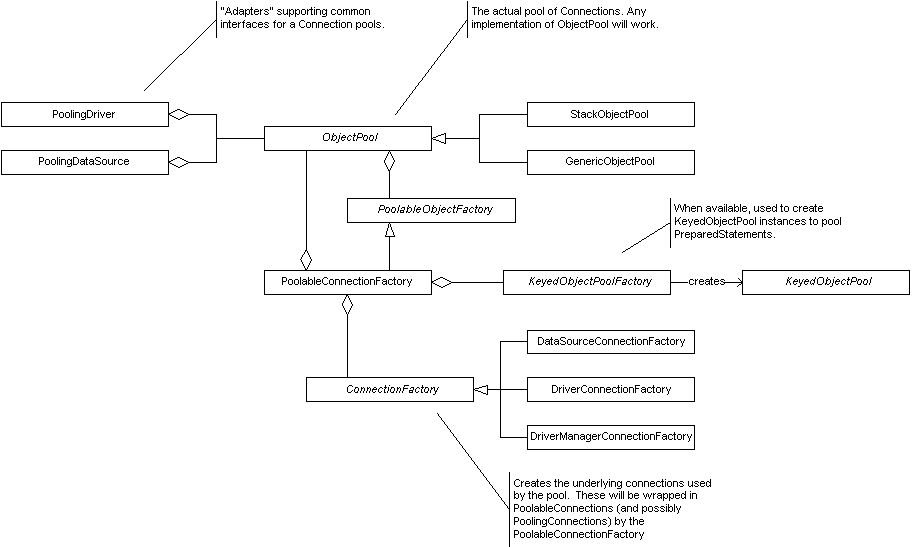
иАМеѓєеЇФзЪД僺豰汆еЙНиАЕйЗЗзФ®зЪДжШѓObjectPool, еРОиАЕжШѓKeyedObjectPool, еЫ†дЄЇдЄАдЄ™жХ∞жНЃеЇУеП™еѓєеЇФдЄАдЄ™ињЮжО•, иАМжЙІи°МжУНдљЬзЪДStatementеНіж†єжНЃSqlзЪДдЄНеРМдЉЪеИЖеЊИе§ЪзІН. еЫ†ж≠§йЬАи¶Бж†єжНЃsqlиѓ≠еП•зЪДдЄНеРМе§Ъжђ°ињЫи°МзЉУе≠ШгАВеЬ®еѓєињЮжΕ汆зЪДзЃ°зРЖдЄК, common-dbcpдЄїи¶БйЗЗзФ®дЄ§зІНеѓєи±°:
дЄАдЄ™жШѓPoolingDriver, еП¶дЄАдЄ™жШѓPoolingDataSource, дЇМиАЕзЪДеМЇеИЂжШѓPoolingDriverжШѓдЄАдЄ™жЫіеЇХе±ВзЪДжУНдљЬз±ї, еЃГжМБжЬЙдЄАдЄ™ињЮжΕ汆жШ†е∞ДеИЧи°®, дЄАиИђйТИеѓєеЬ®дЄАдЄ™jvmдЄ≠и¶БињЮжО•е§ЪдЄ™жХ∞жНЃеЇУ, иАМеРОиАЕзЫЄеѓєзЃАеНХдЄАдЇЫ. еЖЕйГ®еП™иГљжМБжЬЙдЄАдЄ™ињЮжΕ汆, еН≥дЄАдЄ™жХ∞жНЃжЇРеѓєеЇФдЄАдЄ™ињЮжΕ汆.
дЄЛйЭҐжШѓcommon-dbcpзЪДзїУжЮДеЕ≥з≥ї:
дЄЛйЭҐжШѓеПВиАГдЇЖcommon-dbcpзЪДдЊЛе≠РдєЛеРОеЖЩзЪДдЄАдЄ™дїОињЮжΕ汆дЄ≠иОЈеПЦињЮжО•зЪДеЈ•еЕЈз±ї
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
/** * еИЫеїЇињЮжО• * * @since 2009-1-22 дЄЛеНИ02:58:35 */ public class ConnectionUtils { // дЄАдЇЫcommon-dbcpеЖЕйГ®еЃЪдєЙзЪДprotocol private static final String POOL_DRIVER_KEY = "jdbc:apache:commons:dbcp:"; private static final String POLLING_DRIVER = "org.apache.commons.dbcp.PoolingDriver"; /** * еПЦеЊЧ汆еМЦй©±еК®еЩ® * * @return * @throws ClassNotFoundException * @throws SQLException */ private static PoolingDriver getPoolDriver() throws ClassNotFoundException, SQLException { Class.forName(POLLING_DRIVER); return (PoolingDriver) DriverManager.getDriver(POOL_DRIVER_KEY); } /** * йФАжѓБжЙАжЬЙињЮжО• * * @throws Exception */ public static void destory() throws Exception { PoolingDriver driver = getPoolDriver(); String[] names = driver.getPoolNames(); for (String name : names) { driver.getConnectionPool(name).close(); } } /** * дїОињЮжΕ汆дЄ≠иОЈеПЦжХ∞жНЃеЇУињЮжО• */ public static Connection getConnection(TableMetaData table) throws Exception { String key = table.getConnectionKey(); PoolingDriver driver = getPoolDriver(); ObjectPool pool = null; // ињЩйЗМжЙЊдЄНеИ∞ињЮжΕ汆дЉЪжКЫеЉВеЄЄ, йЬАи¶БcatchдЄАдЄЛ try { pool = driver.getConnectionPool(key); } catch (Exception e) { } if (pool == null) { // ж†єжНЃжХ∞жНЃеЇУз±їеЮЛжЮДеїЇињЮжО•еЈ•еОВ ConnectionFactory connectionFactory = null; if (table.getDbAddr() != null && TableMetaData.DB_TYPE_MYSQL == table.getDbType()) { Class.forName(TableMetaData.MYSQL_DRIVER); connectionFactory = new DriverManagerConnectionFactory(table .getDBUrl(), null); } else { Class.forName(TableMetaData.ORACLE_DRIVER); connectionFactory = new DriverManagerConnectionFactory(table .getDBUrl(), table.getDbuser(), table.getDbpass()); } // жЮДйА†ињЮжΕ汆 ObjectPool connectionPool = new GenericObjectPool(null); new PoolableConnectionFactory(connectionFactory, connectionPool, null, null, false, true); // е∞ЖињЮжΕ汆ж≥®еЖМеИ∞driverдЄ≠ driver.registerPool(key, connectionPool); } // дїОињЮжΕ汆дЄ≠жЛњдЄАдЄ™ињЮжО• return DriverManager.getConnection(POOL_DRIVER_KEY + key); } } |
- дЄКдЄАзѓЗпЉЪIBM жАїжЮґжЮДеЄИпЉЪиѓЭиѓіз®ЛеЇПеСШзЪДиБМдЄЪзФЯжґѓ
- дЄЛдЄАзѓЗпЉЪеЄЄзФ®зЪДеЉАжЇРжХ∞жНЃеЇУињЮжΕ汆дїЛзїН
Apache common-poolпЉМcommon-dbcpжЇРз†БиІ£иѓїдЄО僺豰汆еОЯзРЖеЙЦжЮРпЉЪз≠ЙжВ®еЭРж≤ЩеПСеСҐпЉБ
еПСи°®иѓДиЃЇ
------====== жЬђзЂЩеЕђеСК ======------
йЗСдЄЭзЗХзљСпЉМдЄАдЄ™дЄ•и∞®зЪДзљСзЂЩпЉБ
- 2020еєіжЭВи∞И
- гАКиґ£и∞ИshellгАЛињБзІїеЕђеСК
- freemarkerеЖЕеЃєињБзІїеЕђеСК
- дїАдєИжШѓFreeMarkerпЉЯ
- 2019еєідЄЛеНКеєі
- жО®иНРдЄ§жЬђдЄОжХ∞жНЃзїУжЮДзЫЄеЕ≥зЪДдє¶
- дЄАйТИиІБи°Аз≥їеИЧ[17]: жЈ±еЇ¶иІ£жЮРvolatile...
- и∞Ии∞Ие§ІOзЪДе≠¶дє†жЦєж≥Х
- дїОжОШйЗСзЪДи£БеСШзЬЛзЬЛе∞ПеЖМе≠РзЪДдїЈеАЉ
- java8жЦ∞зЙєжАІ[5]пЉЪжЈ±еЕ•зРЖиІ£Java8 La...
- FormatterйЕНзљЃжЦЗдїґзФЯжИРињЗз®Л
- гАКiBATISеЃЮжИШгАЛpdfдЄЛиљљ
- гАКStruts 2.xжЭГе®БжМЗеНЧ(зђђ3зЙИ)гАЛpdfдЄЛ...
- гАКSpringжКАжЬѓеЖЕеєХпЉИзђђдЄАзЙИпЉЙгАЛpdfдЄЛ...
- йЭҐиѓХ姩дЄЛиљѓдїґдїЛзїН
- foreachеТМIterableжО•еП£з†Фз©ґ
- java8жЦ∞зЙєжАІ[2]пЉЪеЖЕйГ®ињ≠дї£еТМе§ЦйГ®ињ≠дї£...
- еИЖеЄГеЉПдЄОе§ІжХ∞жНЃзЪДиЃЊиЃ°дЄОеЃЮзО∞[6]пЉЪи∞Ии∞И...
зГ≠йЧ®жЦЗзЂ†
- SpringдЄ≠@CacheableзЪДзФ®ж≥Х
- Unsupported major.minor version 5...
- BIG5зЉЦз†Б
- SpringдЄ≠DataIntegrityViolation...
- гАКWebеЙНзЂѓйїСеЃҐжКАжЬѓжП≠зІШгАЛpdfдЄЛиљљ
- Class.getResourceеТМClassLoader...
- JREдЄОJDKзЪДеМЇеИЂ
- serialVersionUIDдљЬзФ®
- java String.split()еЗљжХ∞зЪДзФ®ж≥ХеИЖжЮР
- Eclipseж≥®йЗКж®°жЭњиЃЊзљЃиѓ¶иІ£
- jsonжХЩз®Лз≥їеИЧпЉИ5пЉЙ-jsonйФЩиѓѓиІ£жЮРnet....
- jsonжХЩз®Лз≥їеИЧпЉИ4пЉЙ-optXXXжЦєж≥ХзЪДдљњ...
- ArrayListеЊ™зОѓйБНеОЖеєґеИ†йЩ§еЕГзі†зЪДеЄЄиІБ...
- freemarkerз©ЇеАЉзЪДе§ДзРЖ
- log4jдљњзФ®дїЛзїН
жЬАжЦ∞иѓДиЃЇ
еЕНиі£е£∞жШОпЉЪжЬђзЂЩжЙАжЬЙpdfдє¶з±НеТМжХЩз®ЛиІЖйҐСеЭЗжЭ•иЗ™дЇОдЇТиБФзљСпЉМзФ±зГ≠ењГиѓїиАЕеЕ±еРМжРЬйЫЖпЉМдїЕйЩРдЇОдЄ™дЇЇе≠¶дє†дЄОз†Фз©ґпЉМдЄ•з¶БзФ®дЇОеХЖдЄЪзФ®йАФгАВ
еОЯдљЬиАЕе¶ВжЮЬиЃ§дЄЇжЬђзЂЩдЊµзКѓдЇЖжВ®зЪДзЙИжЭГ,иѓЈеПКжЧґеСКзЯ•,жЬђзЂЩдЉЪзЂЛеН≥еИ†йЩ§!
йЗСдЄЭзЗХзљСзЂЩ Copyright (c) 2019 www.swiftlet.net All rights reserved е§Зж°ИеПЈпЉЪдЇђICPе§З14057001еПЈ-1
Powered by swiftlet.